
Detecting traffic

In order to have a chance at winning a race the YetiBorgs need to be able to do more than simply follow the track.
What they have to try and do is overtake the competition.
Actually doing the overtake itself is fairly simple, drive to the left or right of the robot in front.
The tricky part is realising there is a robot in front of us to overtake.
Say we have some robots ahead of us, like this:
The processing we have for identifying the lanes sees them, but they are black like the walls are:
One way to solve this would be to determine the shape of the white areas above, but this has problems:
- Typically this kind of processing takes a fair amount of CPU time
- Difficult to identify two robots obscuring each other
- Needs to be able to see robots facing in different directions
- Identifying robots which are only partially in shot is tricky
So what happens if we just do our normal line matching from this image: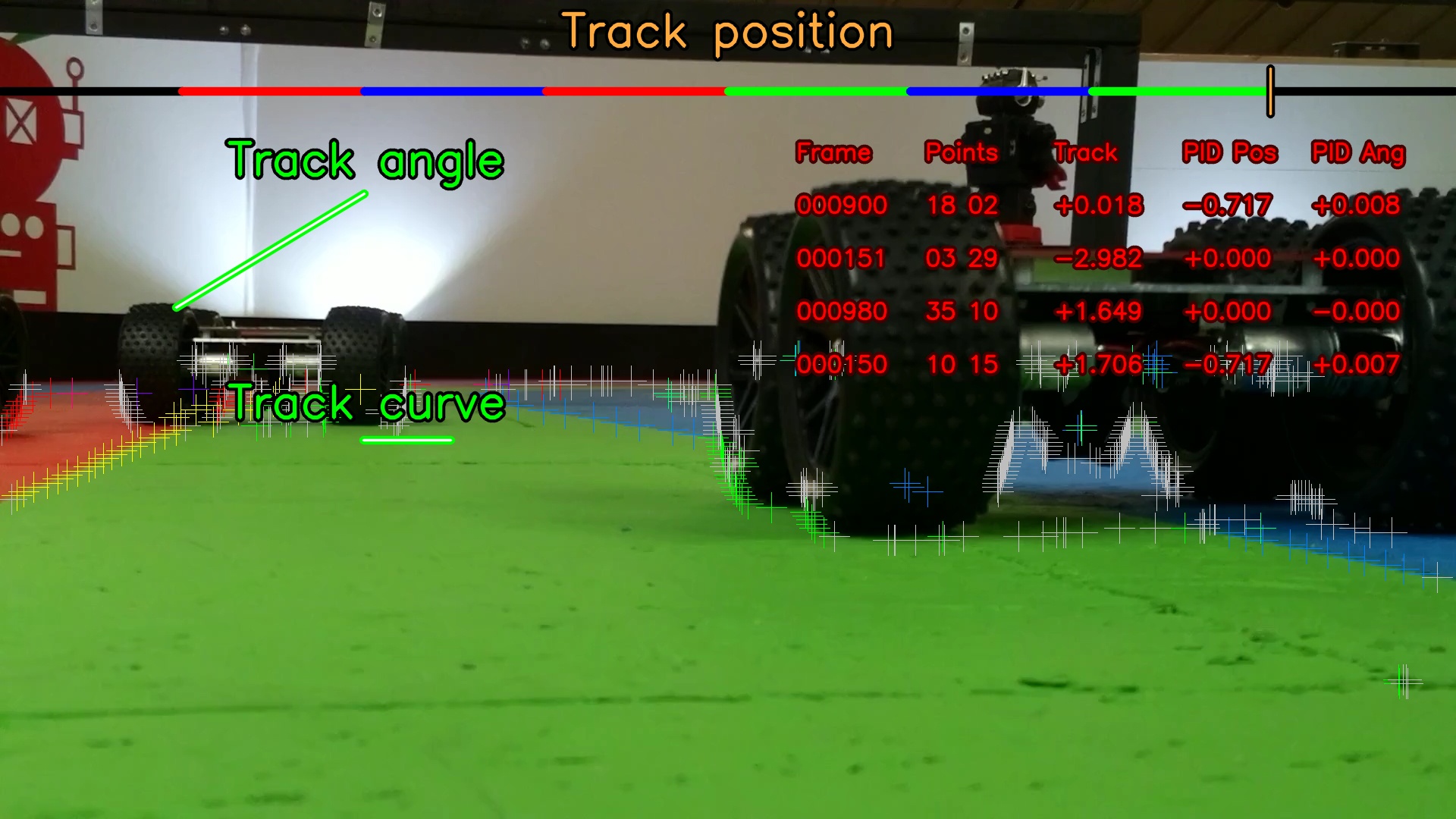
There is actually a fair amount of confusion going on.
First there are points for the "inside wall" marked between the robot tyre and the green lane.
Second there are a large number of grey points in the image.
The grey points are actually quite interesting.
These are the points in the image where we see a colour boundary, but it is not one we expect to find.
For example a blue lane against a wall, or a wall to the right of a red lane.
We get these "error" points in almost all images:
converted to lanes:
converted to points:
These "error" points occur for a number of reasons:
- When the track is nearly horizontal in the image
- At the edge of the image where the next lane is not visible
- Slight imperfections in the track itself
- Lighting differences causing mistakes
Having these is not a problem, usually we simply ignore them when doing the processing.
The difference is how many of these "error" points we see with a robot in front.
What we can do is count how many of these points we see in each image.
If there are enough then there is a robot / obstacle that needs to be driven around.
Not enough then we can keep going as we are.
We can then throw the unneeded points away and continue with the normal processing code.
The only question remaining is do we move to the left, or to the right.
Looking at the points again we can see that there are more on a closer robot:
What we can do is take the average of where all the "error" points are along the X axis (left ↔ right) of the image.
If they are generally on the left we move to the right, otherwise we move to the left instead.
We can work this out using numpy to do the averaging for us:
import numpy imageCentreX = imageWidth / 2.0 # At some point 'others' is loaded with the error points # in the format [[X, Y], [X, Y], ..., [X, Y]] if not overtaking: # Check if we need to overtake a robot in front errorPointCount = len(others) if errorPointCount > errorPointThreshold # Robot detected, decide if we should overtake to the left or right overtaking = True errorPointAverageX = numpy.array(others)[:,0].mean() if errorPointAverageX < imageCentreX: # Robot to the left, overtake to the right # ... else: # Robot to the right, overtake to the left # ... else: # Keep overtaking until we think we passed the robot # ...
Now our YetiBorg knows there is one or more robots ahead and which side it should try and overtake on.
Add new comment